Il s'agit d'implťmenter 2 stratŤgies de rťduction des expressions du lambda-calcul pur:
- la stratťgie NOR jusqu'ŗ obtenir une Forme Normale (ťvaluation paresseuse)
- la stratťgie AOR jusqu'ŗ obtenir une Forme Normale Faible (ťvaluation affairťe).
- Dťfinir un type CAML qui reprťsente les expressions du lambda-calcul pur
- Ecrire, en utilisant ce type, quelques fonctions CAML qui construisent des lambda-expressions simples comme:
x.x ou
- Ecrire une fonction qui, dans une expression exp, remplace toutes les occurrences libres d'une variable y par une autre expression exp1
- Ecrire une fonction qui applique la rŤgle de bťta-conversion
- Ecrire une fonction qui rťduit une expression ŗ une FNF.
On peut imaginer 2 faÁons de reprťsenter un graphe orientť:
- par une liste d'arcs entre 2 sommets
- par une liste de sommets et une fonction qui ŗ un sommet (origine) associe une liste de sommets (destination)
Il s'agit de:
I) dťfinir un type pour chacune des rťprťsentations
et ťcrire les fonctions permettant de changer de reprťsentation
II) pour chacune des 2 reprťsentations, ťcrire une fonction qui compte le nombre de chemins entre 2 sommets.
III) gťnťraliser et trouver 2 reprťsentations pour des graphes oý chaque arc est affectť d'une longueur,
et pour chacune de ces 2 reprťsentations,
ťcrire une fonction qui trouve le plus court chemin entre 2 sommets.
Il s'agit de gťnťraliser les fonctions sur les arbres binaires (avec au plus 2 sous-arbres) aux arbres quelconques (avec un nombre quelconque de sous-arbres).
Pour cela, dťfinir un type pour les arbres quelconques, puis:
I) Dťfinir les fonctions permettant de dťcompter:
- le nombre de feuilles
- le nombre de noeuds
- le nombre d'arcs
II) Dťfinir les fonctions qui retournent la liste des sommets rencontrťs lors d'un parcours:
- prťfixť (en profondeur d'abord)
- infixť
- postfixť
- en largeur d'abord
Le codage de Huffman permet de comprimer un fichier texte.
La compression de donnťes est utilisťe pour augmenter les capacitťs de stockage en mťmoire ou les vitesses de transmission.
La compression est composťe d'un encodage et d'un dťcodage. Il faudra donc ťcrire ces 2 fonctions.
Voir ici ou ici pour une description dťtaillťe du codage de Huffman.
Il s'agit d'ťcrire certaines fonctions sur des arbres qui peuvent comporter un nombre infini de noeud et dont le type est donnť ci-dessous:
type ('a,'b) ftree = Null | Node of 'a * ('b -> ('a,'b) ftree);;Un arbre infini est:
- soit vide (Null)
- soit un noeud avec:
. une valeur de type 'a
Ecrire une fonction maptree qui applique une fonction sur toutes les valeurs d'un arbre infini (de faÁon similaire ŗ la fonction map pour les listes).
. un nombre quelconque de sous-arbres, chacun ťtant ťtiquetť par une valeur de type 'b
(on choisit d'utiliser une fonction de type 'b -> ('a,'b) ftree plutôt qu'une liste de type ('b * ('a,'b) ftree) list)
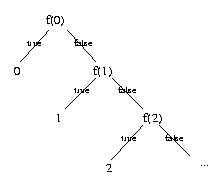
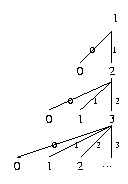
Ecrire les fonctions permettant de dťfinir les arbres dessinťs ci-dessous (ťtant donnťe une fonction f):
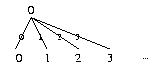
Il s'agit d'implťmenter un systŤme de rťťcriture cŗd un systŤme permettant d'appliquer de faÁon automatique des rťgles de rťťcriture.
Dťfinitions prťlimnaires:
Un terme est construit ŗ partir de constantes, de variables et d'opťrateurs.
Un terme t1 filtre un terme sans variable t2 ssi il existe une substitution s telle que s.t1 = t2.
Une rŤgle de rťťcriture s'ťcrit t1 -> t2 oý t1 et t2 sont des termes avec variables.
Soit t un terme sans variable. La rŤgle t1 -> t2 s'applique ŗ t si t1 filtre un sous-terme, disons tr, de t.
Alors, le rťsultat de l'application de la rŤgle est t dans lequel tr a ťtť remplacť par s.t2, oý s est la substitution telle que s.t1 = tr.
Exemple:
La rŤgle x * (y + z) -> x * y + x * z appliquťe au terme b + a * (b + c) * d + a * c
donne le terme b + (a * b + a * c) * d + a * c.
Il s'agit de:
- Reprťsenter termes, rŤgles de rťťcriture, et substitutions
- Ecrire une fonction qui:
- filtre un terme par un autre : le rťsultat est une substitution (ou une exception si le filtrage ťchoue).
- Tester sur l'exemple suivant:
- applique une rŤgle sur un terme (sans variable) : le rťsultat est un terme sans variable (ou une exception si la rŤgle ne s'applique pas).
- applique une liste de rŤgles sur un terme : le rťsultat est le terme obtenu en appliquant la premiŤre rŤgle de la liste qui s'applique.
- applique une liste de rŤgles sur un terme jusqu'ŗ ce qu'aucune des rŤgles de la liste ne s'applique plus.
RŤgles:
1 * x -> x (1/x) * x -> 1 (x * y) * z -> x * (y * z) (1/x) * (x * y) -> y x * 1 -> x (1/1) -> 1 (1/(1/x)) -> x x * ((1/x) * y) -> y (1/(x * y)) -> (1/x) * (1/y)Terme: (1/((1/a) * (1/b)))
Il s'agit d'implťmenter un petit langage fonctionnel ŗ ťvaluation paresseuse. Il s'agit donc d'ťcrire un analyseur syntaxique et un interprťteur pour ce langage. Pour ťcrire l'analyseur syntaxique, on se servira de camlyacc (cf. documentation sur ocaml).
Un programme dans ce langage est une suite de dťfinitions de fonctions de la forme suivante:suivie d'une expression ŗ ťvaluer. La syntaxe d'une expression est la suivante (en BNF):
Soit<nom_fonction>(<var1>,<var2>,...,<varn>) =<expr>.
Exemple: dans ce langage, on peut ťcrire le programme suivant:
<expr> ::= <var> (variable) | <nom_fonction> (<expr1>,<expr2>,...,<exprn>)(application) | 0|1|2| ...(entiers) | vrai|faux(boolťens) | si<expr>alors<expr>sinon<expr>(conditionnelle) | <expr> ( +|-|*|/|<=|=>|<|>|=) <expr>(opťrateurs binaires) | ( +|-) <expr>(opťrateurs unaires) | (<expr>)(parenthŤsage) Soit ou_logique(x,y) = si x alors vrai sinon y. ou_logique((75>0),(75/0=75))Ce programme comporte la dťfinition de la fonctionou_logiqueet une expression ŗ ťvaluer. L'ťvaluation de cette expression donne le rťsultatvrai, parce que conformťment au procťdť d'ťvaluation paresseuse, l'expression(75/0=75)n'est pas ťvaluťe.