Jean Christophe Beyler

ICPS - LSIIT
Pôle API
Boulevard Sébastien Brant
F-67400 ILLKIRCH
Bureau B253b
Tel: (+33) (0)3 90 24 45 52
E-mail : beyler@icps.u-strasbg.fr
ESODYP
ESODYP is a dynamic optimizer that models data access behaviour and prefetches the data in advance. It is a dynamic predictor that builds a graph of memory strides and uses the graph to predict the next access strides. When associated to a memory access load, the system is able to insert prefetches that reduce the cost of the load.
This page explains how to install, use and modify the ESODYP framework.
Downloading
The first thing to do is to download the ESODYP framework. There are currently 4 different versions of the framework that are available. Here is a brief presentation of the different systems:
-
The stride version is the basic version. This is actually the first version of the system and handles the modelization of memory strides in a program. The system automatically creates the Markov model and prefetches data when the current behavior is predictable.
-
The address version is a second version and only has a slight modification compared to the first version. Instead of modelizing memory strides, this version modelizes absolute addresses. Like the first system, it creates the Markov model and prefetches data when the current behavior is predictable.
-
The structure version is a more complex version. It uses a structure to define the elements that are modelized which gives the user the chance to modify the structure and handle any type of data. The user only has to define a few functions to modify the internal representation of the modeled elements.
-
The manager version gives the programmer the chance to easily test different parameters in order to find the best parameters for a particular program and memory behavior. It uses the stride version of the ESODYP framework.
Installing
Once one of the versions has been downloaded and extracted, a simple make will compile the system with a program example that uses the model.
Warning: the ESODYP stride version was written for the Itanium processor. The system automatically inserts prefetch instructions into the instruction flow of the program. Since the prefetch instruction is dependent of your architecture, you must modify this line.
For example, using the GNU gcc compiler on the Itanium processor, the code in question is:
//inline prefetch function
inline void Markov_PrefetchItNoReally(void* x)
{
//only lfetch
__asm__ __volatile__ (
"lfetch [%0]\n"
::"r" (x)
);
}
However, on x86-assembly processors, this code would be for example:
//inline prefetch function
inline void Markov_PrefetchItNoReally(void* x)
{
//only lfetch
__asm__ __volatile__ (
"prefetchnta (%0)\n"
::"r" (x)
);
}
A quick look at the architecture instruction set of the target processor will give the right instruction to use.
Integrating the ESODYP model in your program
To explain how the ESODYP model can be integrated into your program, this section will use a simple example. Let us imagine that the program is originally a simple sum of a two dimension array:
#include <stdio.h>
#include <stdlib.h>
#define L 90
#define M 50000
#define N 40
int main(void)
{
int t[M][N];
int sum =0;
int h,i,j;
/* Init */
for(i=0;i<M;i++) {
for(j=0;j<N;j++) {
t[i][j] = i*j;
}
}
/* Sum */
for(h=0;h<L;h++) {
for(j=0;j<N;j++) {
for(i=0;i<M;i++) {
sum += t[i][j];
}
}
}
printf("Sum %d \n", sum);
return EXIT_SUCCESS;
}
This is only a simple example but we can suppose that in this case, the access to t[i][j] is costly. We will want to modelize it and insert prefetches to reduce the number of cache misses.
Including the header
As for many libraries, a single line is needed to include the ESODYP library functions. This line can be put at the beginning of the target program file.
#include "Markov_stride.h"
Initialization
The ESODYP model uses a structure named SMarkov. The allocation of a SMarkov structure is done dynamically. Here is the function that must be called:
//Initialize memory
SMarkov* m = Markov_Initialize();
Once the structure is initialized, it can directly be used to modelize memory behavior and prefetch data. In our example, the costly load is this instruction:
sum += t[i][j];
To study and optimize the access, this can be added:
m->fct(m, &(t[i][j]));
sum += t[i][j];
As you can see, the structure SMarkov contains a function pointer that will handle the call to the right library function internally. The programmer does not need to handle this directly.
Parameters
Though the basic usage of the system is easy, certain parameters can be defined by the user. For example, the number of elements used to calculate the predictions can be modified. This parameter is called the order, or depth of construction, of the model. Every parameter that the user can change is performed by the Markov_Set function. The following code shows how to modify the default order value:
Markov_Set(m,2,M_CONSDEPTH); //Set depth of construction
The Markov_Set function has the following prototype:
void Markov_Set(SMarkov *m, int v, int mask); //Set certain attributes
The first parameter m is the Markovian model that the user wants to modify. The second parameter v is the value that will be set. Finally, mask is the parameter that tells the function what internal value is to be modified. The different possibilities for the mask are:
- M_CONSDEPTH: order, or depth of construction, of the model. This value determines how many elements are to be used to calculate a prediction. The default value is 2;
- M_ERRMAX: number of consecutive miss predictions before the model is flushed and a new one is constructed. The lower the number, the more models will be constructed during the execution of the program if the behavior is not very predictable. However, if the number is too high, it will take a lot of miss predictions before the model is updated. The default value is 20;
- M_CONSTTL: time-to-live of the construction. This parameter determines the number of elements used to construct the model before starting to prefetch. The default value is 30;
- M_PREFDIST: prefetch distance of the system. This gives the model the number of elements between the predicted element and the current one. The default value is 3;
Clearing the model
Once the model is no longer necessary, it may be cleared from memory using the following function:
Markov_Clear(m);
Going even further
This section presents a few advanced usages of the ESODYP framework.
Manually resetting the model
If the user knows that the model should be resetted, because he can determine a phase change of the memory behavior for example, he can directly call the Markov_Reset function to reset the model. It will start constructing a new model after the call.
void Markov_Reset(SMarkov *m); //Reset the model
Resetting the current address
The model uses the current address to calculate the next stride. In certain cases, it can be justified to modify that current address before really calling the model. For example, let us assume the memory stride sequence is:
1024 4 12 20 4096 4 12 20 24024 4 12 20.
It is clear that the main pattern is the following stride sequence: 4 12 20. However, the big jumps between the patterns will only pollute the model. By setting the address before each jump, the model will modelize the following sequence:
0 4 12 20 0 4 12 20 0 4 12 20
This final sequence is easier to modelize and the ESODYP framework will consume less memory. The function that allows to modify the base address is:
void Markov_SetAddress(SMarkov* m, void *address);
Outputting information about the graph
This section will explain how to gather information about the constructed graph. Two functions can be used:
int Markov_OutputGraph(SMarkov *m); //Output graph to terminal
int Markov_OutputGraphDot(SMarkov *m, const char *fname); //Output graph to .dot format
The first function writes the graph information directly in the terminal, whereas the second writes the graph under the DOT format. For example, the previous two-dimensional array traversal will create this DOT file:
digraph {
size="8,8";
3084730456 [label="(0)\n 160",shape=box,color=red,style=filled]
3084730456 -> 3084730508 [fontcolor=blue,label ="3599"]
3084730508 [label="(1)\n 160"]
3084730508 -> 3084730508 [fontcolor=blue,label ="179989170"]
}
This dot file can be used with the graphviz package to create this graph:
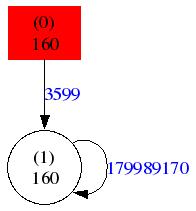 As we can see, there are only two nodes since the memory behavior is relatively simple. The ESODYP model contains multiple orders at the same time. The red node is a first order node, which means that, if the model is in that state, it only considers the last stride to calculate the predictions. The white nodes are nodes of a superior depth. The number in parenthesis is the depth of the node. The number underneath is the stride that the node represents. Finally, the edge values are the number of times the model went from one node to another.
As we can see, there are only two nodes since the memory behavior is relatively simple. The ESODYP model contains multiple orders at the same time. The red node is a first order node, which means that, if the model is in that state, it only considers the last stride to calculate the predictions. The white nodes are nodes of a superior depth. The number in parenthesis is the depth of the node. The number underneath is the stride that the node represents. Finally, the edge values are the number of times the model went from one node to another.
However, if we consider the following loop:
for(j=0;j<N;j++) {
for(i=0;i<M;i++) {
sum += t[(3*i+4)%M][(2*i+5*j)%N];
m->fct(m,&(t[(3*i+4)%M][(2*i+5*j)%N]));
}
}
The access pattern is more complex. This has a direct impact on the model obtained:
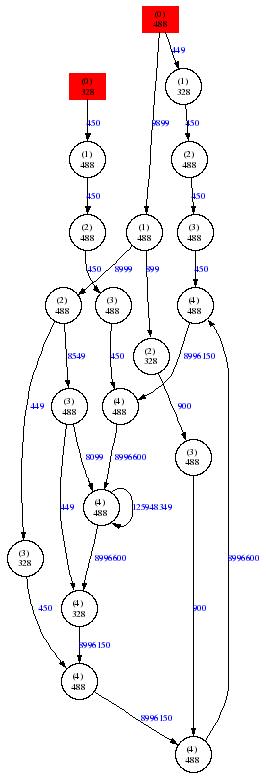
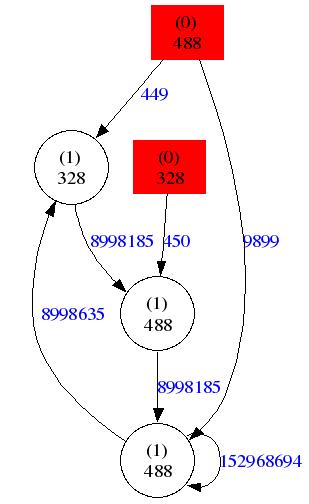 Finally, if we consider the same sequence but set the order of the model to 5 and set the time to live to 5000, we obtain the following graph:
Finally, if we consider the same sequence but set the order of the model to 5 and set the time to live to 5000, we obtain the following graph:
Modifying the base behavior
Finally, in order to have the best performance of the model, different versions exist using defines in the header file. Here is a presentation of their significance. Commenting the corresponding line removes the option.
-
__DEBUG__: this is a verbose mode. Use it if you want to understand what is happening;
-
__NORMAL_VERB__: this is a semi-verbose mode. It gives less information than in debug mode;
- __OPT_VERIF__: this option sets a verification of the model and prints out information about the prediction accuracy;
-
__PREFETCH__: sets prefetching on. Otherwise the model simply modelizes the behavior and does not try to optimize the program. Generally used to calculate the overhead;
-
__DRAW_DOT_FILES__: automatically creates two dot files. One at the end of the construction and one if the model was cleared.
The structured version
The structured version is probably the most interesting version of the ESODYP framework since it is the easiest to modify to a new user's needs.
Redefining the structure
Here is the structure representing an address structure with a high value and a low value:
/*Instead of having a single stride as information, we'll do an abstraction using a structure */
typedef struct sGlobalAdd {
u_int32_t high;
u_int32_t low;
} SGlobalAdd;
Modifying the dependent functions
To use this structure in the ESODYP framework, the only functions (located in the .c file) that will actually access the internal fields are:
static void INFO_print(SGlobalAdd* info)
static void INFO_reset(SGlobalAdd* info)
static int INFO_isNull(SGlobalAdd* info)
static void INFO_OutputFile(FILE* f,SGlobalAdd* info)
static int INFO_compare(SGlobalAdd* a, SGlobalAdd* b)
This means that if there is a need for a different representation, these are the only regions of the code that must be changed. Here is the explanation of each function:
- INFO_print(a): prints out the information from structure a to the terminal;
- INFO_reset(a): sets the fields from structure a to a Null setting. Basically, with the settings put in place when INFO_reset is called, INFO_isNull should return 1. If something is changed in the structure, INFO_isNull should return 0;
- INFO_isNull(a): function returns 1 if the structure a represents the Null structure (reference point). It returns 0 otherwise;
- INFO_OutputFile(f,a): outputs information from structure a into a file f. This function can have the same output as the INFO_print function;
- INFO_simplecompare(a,b): function returns 0 if the elements a and b are not equal, returns 1 otherwise;
- INFO_compare(a,b): function works like strcmp. Returns -1, 0 or 1 if a is respectively considered less than, equal to or greater than b.
PREFETCH_FUNCTION
Finally, the predictions will call a function called PREFETCH_FUNCTION. This function will need to be filled with the assembly code shown above or another mechanism if a prefetching/optimization scheme is to be used.
Once the structure is updated, the PREFETCH_FUNCTION function competed and the different INFO_* functions have been redefined, the system will be operational.
Conclusion
The ESODYP framework is able to modelize behavior and can handle various element sequences. It can be used to prefetch data but also to simply modelize data sequences to determine if they are predictable or not.
The system is totally automatic, internalizing as much as possible to simplify the work of the user. However, the user can define certain parameters to modify the default behavior of the system. More advanced users can of course directly modify the source code that is well commented in order to achieve their own goals.
If there are any questions, do not hesitate to contact the author Jean Christophe Beyler at beyler (at) icps dot u-strasbg dot fr.